
Conversemos de DevSecOps
En esta nueva sección de nuestro blog compartiremos la visión y experiencia de nuestro equipo de expertos en el ámbito del desarrollo de software y las tecnologías de información en general, quienes tocarán distintos temas relacionados con las tecnologías y metodologías utilizadas por Sovos para crear e implementar un mejor software, y entregarán tips y datos orientados a aportar valor a quienes deben trabajar en este ámbito, fundamental para las compañías que crean y utilizan soluciones para impulsar el negocio de sus clientes.
Pamela Ruiz, Senior QA Engineer
Aplicación de pruebas de performance de API en proyectos de Sovos
En estos tiempos, donde el mercado es muy competitivo, la calidad pasó a un primer plano en la evaluación que realizan los clientes para elegir un producto.
La rapidez en los tiempos de respuesta de servicios o eventos ha cobrado mucha relevancia, a tal punto que -y según se ha analizado estadísticamente- es muy probable que un usuario abandone un producto si debe esperar más de 3 segundos.
Para entregar siempre las mejores soluciones a sus clientes, uno de los focos de Sovos en el área de calidad está puesto en las pruebas de performance. En esta línea se armaron equipos dedicados exclusivamente a todas las tareas no funcionales, que trabajan estrechamente con el equipo de CloudOps para contar con la infraestructura necesaria tanto para las etapas de desarrollo, como las finales, incluyendo producción.
Una de las primeras tareas que tuvo el equipo de performance fue el desarrollo, precisamente, de un framework para pruebas de performance. En Sovos se utilizan 2 herramientas open source, K6 y Jmeter, para el desarrollo de scripts para pruebas.
Los resultados de estas pruebas se guardan en InfluxDB, una base de datos especialmente diseñada para almacenar datos de este tipo. Grafana es la herramienta elegida para consumir los datos almacenados y procesarlos para mostrarlos mediante gráficos y tablas.

La estrategia utilizada para el desarrollo de pruebas se basa, primeramente, en evaluar los endpoints más utilizados por los usuarios, testearlos bajo diferentes cargas y analizar los resultados, no solo en cuanto a tiempos de procesamiento, sino también, en cantidad de errores obtenidos provocados por la concurrencia.
Es recomendable que para el análisis de los resultados se cuente con herramientas de monitoreo como AppDynamics o Jaeger, que muestran en tiempo real lo que sucede con cada componente del sistema, permiten seguir el flujo de algunos requests para observar la distribución de tiempos que ocupa en todo su procesamiento e identifican si alguno de ellos está provocando cuellos de botella.

En la imagen se observa el trace de un request desde Jaeger.
También observamos qué sucede a nivel de base de datos; si hay bloqueos, si algún pedido necesita índices para alguna tabla, si el pool de conexiones es suficiente, etc.

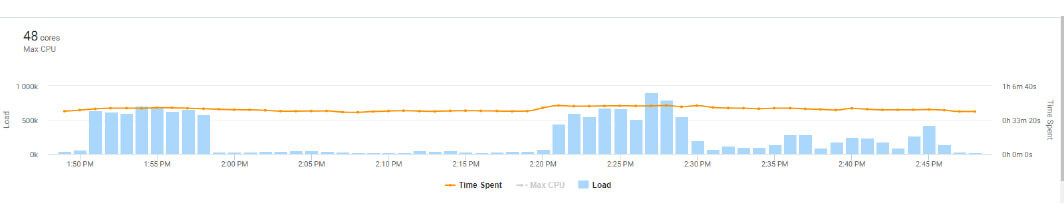
En la imagen se observa la utilización de recursos de base de datos desde AppDynamics.
Durante esta primera etapa de análisis se realizan las tareas de forma manual, probando diferentes escenarios. Por ejemplo, aumentando los usuarios concurrentes de forma gradual, partiendo desde 10, hasta llegar a 100 o 150 usuarios sucesivamente en el caso de un ambiente pequeño.
A continuación, desarrollaremos un ejemplo implementado en uno de los proyectos de Sovos:
Como primer paso se desarrolla el script implementando un setup -que es común a todos los scripts- por lo que se utiliza el llamado a un script externo para evitar la duplicidad de código.
Luego de realizado el setup, se ejecuta la prueba en donde establecemos el endpoint a utilizar junto con sus headers, y también se le agrega una corroboración de que la respuesta sea la que estamos esperando. Estas comprobaciones de respuesta se aplican en todos aquellos casos en los que tenemos requests dinámicos, para asegurar no solo que devuelve el código http esperado, sino también, que contamos con la información requerida.
Generamos un reporte csv con las métricas de las pruebas, así como también un reporte de errores XML en el se registra qué datos se enviaron, el código de respuesta obtenido y el cuerpo del mensaje de respuesta.
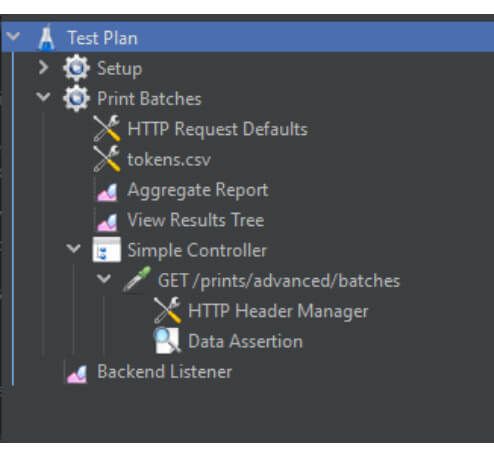
Imagen del test plan desde Jmeter.
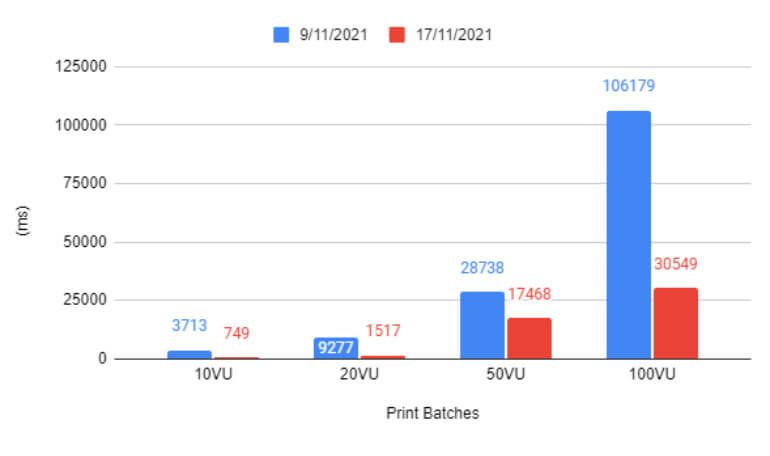
Resultados de las pruebas antes y después de los cambios de código.
En uno de nuestros endpoints realizamos una primera ejecución en el ambiente de QA con distintos escenarios, variando la cantidad de usuarios concurrentes entre 10 y 100 usuarios. Se encontraron mejoras para realizar a nivel de código y se ejecutaron nuevamente las mismas pruebas para poder comparar el impacto de los cambios realizados.
En este caso tuvimos una mejora notable, observando una disminución en los tiempos promedios de respuesta de 100 segundos a 30 segundos en el escenario de mayor concurrencia (100 usuarios virtuales).
De esta manera, encontramos los endpoints más críticos, para poder trabajar sobre ellos y aplicar mejoras.
Luego de esta primera etapa, procedemos a establecer corridas automáticas de forma semanal durante la noche para evitar bloquear los ambientes bajos. Estas corridas se realizan para mantener el control y detectar los problemas de performance antes de que lleguen a producción, donde principalmente observamos si los cambios realizados durante ese tiempo tuvieron impacto a nivel de performance. Luego de algunas ejecuciones, se establecen umbrales aceptables de variación, para alertar cuando en algún momento se supera alguno de esos umbrales.




