
Conversemos de DevSecOps
En esta nueva sección de nuestro blog compartiremos la visión y experiencia de nuestro equipo de expertos en el ámbito del desarrollo de software y las tecnologías de información en general, quienes tocarán distintos temas relacionados con las tecnologías y metodologías utilizadas por Sovos para crear e implementar un mejor software, y entregarán tips y datos orientados a aportar valor a quienes deben trabajar en este ámbito, fundamental para las compañías que crean y utilizan soluciones para impulsar el negocio de sus clientes.
Pamela Ruiz, Senior QA Engineer
Medición y visualización de performance para procesos batch
Por lo general, al medir performance de nuestras APIs, en Sovos buscamos obtener distintas métricas, como tiempos de respuesta, cantidad de errores, transacciones procesadas por minuto, cuellos de botella en el flujo y recursos utilizados en los servidores, entre otros. La finalidad es realizar un análisis de los datos obtenidos y aplicar mejoras en nuestros productos, para proveer la mejor calidad a nuestros clientes.
Para ello utilizamos herramientas como JMeter y K6, entre otras, para la ejecución de pruebas; AppDynamics para el monitoreo en tiempo real y Grafana e InfluxDB para la recolección y muestra de datos.
En este caso, como base de datos para almacenar las métricas, se seleccionó InfluxDB, la que es utilizada específicamente para almacenar información de métricas y datos para análisis en tiempo real. Esta herramienta de almacenamiento es plenamente compatible con Grafana, utilizada para detallar los resultados mediante gráficos.
A diferencia de las API, al medir la performance de procesos batch -que por lo general corren en modo background como servicios o procesos de Windows/Linux- no es tan relevante el tiempo de respuesta de estos procesos (aunque a veces es útil tener el dato para saber la capacidad de procesamiento de nuestro sistema), ya que el cliente no se encuentra activamente esperando una respuesta, sino que se evalúan principalmente métricas como recursos utilizados durante el procesamiento.
Para este tipo de pruebas se realizan una serie de pedidos para encolar procesos batch, y analizar el comportamiento del sistema durante el procesamiento. En nuestro caso, utilizamos JMeter para simular a usuarios realizando los pedidos.
Para la medición de recursos utilizados en un servidor usamos Telegraf, un agente que se instala en los servidores (en nuestro caso Windows) y se comunica con InfluxDB.
Dentro de los productos de Sovos utilizamos los llamados batch processing. Estos son procesos tipo batch que toman desde unos pocos minutos hasta varias horas en completar su ciclo, dependiendo del volumen de datos a procesar. Por lo general son utilizados para importar, transformar, exportar o transmitir altos volúmenes de datos.
Para su funcionamiento, el cliente envía un pedido para iniciar este proceso y recibe un acknowledgment para saber que su pedido fue tomado con éxito.
Por detrás, comienza el proceso con un orquestador de procesos que maneja los pedidos, encolándolos y derivándolos al primer procesador que se encuentre disponible, asignándoles el estado de claimed.
Los batch processing trabajan como una máquina de estados, pasando por diferentes estados. En la imagen podemos observar un esquema simplificado de los mismos.
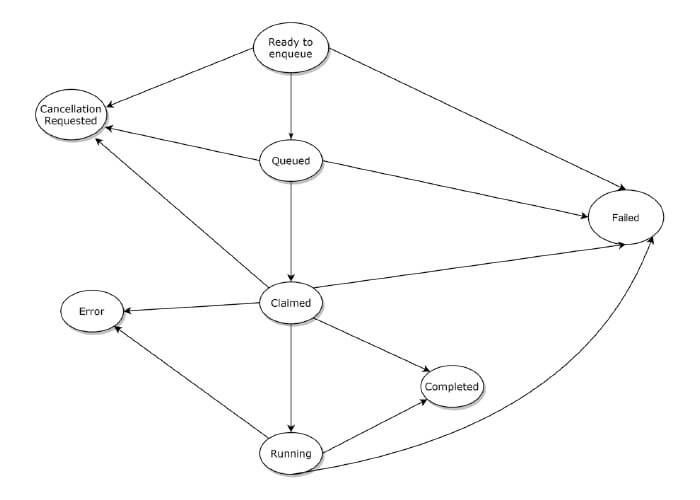
Para nuestro equipo era esencial contar con métricas relacionadas con estos procesos de larga duración, que incluyen:
- Utilización de recursos usados durante los procesos
- Estimación de tiempos promedios de procesamiento
- Análisis de la cantidad de jobs procesados en un determinado momento
- Verificación de los jobs con fallas
Si bien no contábamos con ninguna herramienta para monitorear las métricas que necesitábamos en cuanto a tiempos y cantidades, notamos que durante el procesamiento se utiliza una tabla en la base de datos para registrar los distintos cambios de estado durante todo el proceso.
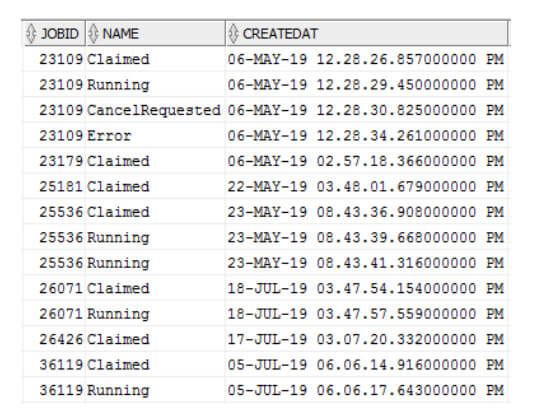
El equipo de trabajo pudo tomar ventaja de ello y utilizar esta tabla como base para obtención de métricas.
Se crearon diferentes consultas a la base de datos para obtener datos tales como:
- Tiempos de ejecución (para el calculo de cantidad de registros procesados por segundo)
- Cantidad de jobs en procesamiento
- Cantidad de jobs fallidos
- Cantidad de jobs encolados
Se tomaron en cuenta los estados principales, como enqueued, running, failed y completed.
Este trabajo podía llevarse a cabo de forma manual y en el momento, pero no era un proceso eficiente a la hora de realizar un análisis de lo sucedido a lo largo del tiempo. Se requería una herramienta que pudiera procesar los datos y mostrarlos de forma amigable mediante gráficos.
De esta manera, para automatizar el proceso de análisis de los resultados y contar con un historial de información, se creó una aplicación con node.js en la que establece una conexión con la base de datos de Oracle, desde donde se extraen las métricas, y una conexión con InfluxDB, en donde se almacenan los datos una vez procesados.
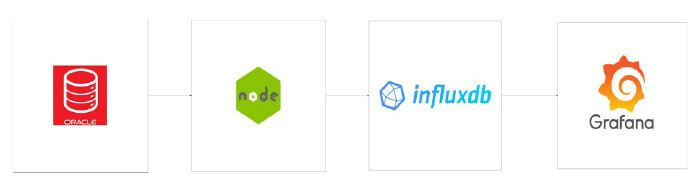
Este proceso de node se realiza cíclicamente cada 20 segundos para recolectar los datos.
Se armó un dashboard en Grafana para mostrar los resultados, tal como muestra la siguiente imagen:
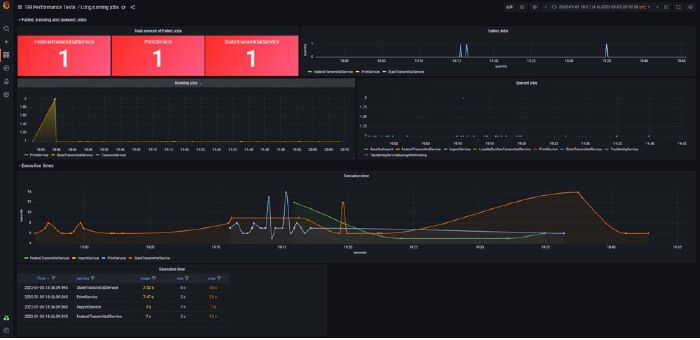
Estos gráficos son totalmente configurables y es posible ajustar a diferentes fechas y horas, de acuerdo con lo que se necesite analizar.
Adicionalmente, esta aplicación se encuentra dockerizada para facilitar el deployment mediante Puppet. Si bien hoy en día está configurada para utilizar en un ambiente específico, en un futuro podríamos aplicar nuevas configuraciones para diferentes ambientes y base de datos según se necesite.
Además pueden agregarse nuevas consultas a la base de datos en caso de que se requieran nuevas métricas, incluyendo números de procesos cancelados por el usuario y número de procesos en algún estado en específico, entre otras.
A continuación se observa un dashboard en Grafana para monitoreo de utilización de recursos:
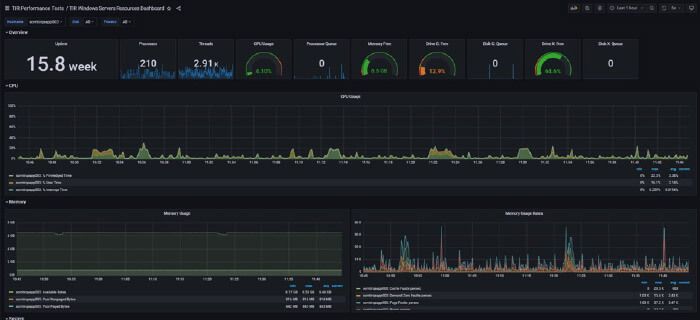
En conclusión, se logró crear un framework de monitoreo para los procesos de larga duración basados en tecnologías open source.
Cada nuevo conocimiento y avance va sumando para tener una mejor base de monitoreo y mejor información al momento de realizar un análisis más profundo al encontrar errores o al realizar pruebas de carga, permitiendo encontrar con mayor facilidad los cuellos de botella, tanto para nuestras APIs como para nuestros procesos de batch.




